
Inside the Language Machine
Why LLMs work—and why they don’t

We see faces in clouds, souls in ships—and now, apparently, introspection in autocomplete.
Anthropic found that Claude’s self-reports correlate with internal states.1 But “introspection” smuggles in more than correlation proves: the model might be pattern-matching “how humans talk about thinking” rather than examining its own cognition. The distinction matters.
TL;DR: LLMs don’t “think”; they ride the London Tube map of human language. Prompts drop you at a station; next-token prediction follows the rails already laid. The map encodes logic, causality, recipes, chess notation—so the ride looks smart, but the train never leaves the tracks. No frame-breaking, no self-awareness. The miracle isn’t the machine; it’s the millennia-old transit system we encoded in words.
Meanwhile, we overlook the real magic: language itself. Not raw data to mine, but accumulated knowledge laid down over millennia. Human language already encodes world models, cause-and-effect relationships, logical structures. LLMs succeed not by building understanding from scratch, but by learning to navigate what’s already there.
This post builds on ideas from The Language Machine. You don’t need to read that first, but it might add context.
If you just want the theory, then head to The Nerdcore Revelation at the end of this post. 700 words—no fat, no filler.
The Structure We Miss
By “structure,” I mean recurring patterns—from conversational turn-taking to theorem-proving—that make language navigable rather than noise.
Take telephone conversations. Edison standardised “hello” in 18772—not arbitrary choice, but weight-bearing structure. Turn-taking, recovering from misunderstanding, signalling you’re listening: all required conventions. These conventions structure conversation.3
Structure exists at every scale. Citations follow conventions. So do topic sentences, legal briefs, recipes, IKEA manuals, liturgical calendars, chess notation. Language is pre-structured, densely and redundantly, across every domain.
The structure isn’t just out there. It’s captured, with surprising fidelity, in the geometry of LLMs.
The Map That Preserves Structure
Recent research connects this structure to what LLMs actually do. “Language Models are Injective and Hence Invertible”4 proves that different prompts lead to different final-layer hidden states—meaning the model’s internal geometry preserves distinction in input.5 This internal geometry is what researchers call “latent space”—the high-dimensional mathematical space where the model represents meaning. No two prompts collapse to the same point.
Injectivity means the map preserves difference—no two distinct sentences collapse into the same internal state—allowing the model to reconstruct meaning from geometry.6 This mapping coexists with compression—but it’s compression of patterns, not facts. The model abstracts by distilling relational geometry, not by memorising or erasing content. It learns how meanings connect, not what the meanings are.
This explains observed behaviour. Why does changing a single word sometimes dramatically shift output? Because “cat” and “cat.” and “orange cat” map to genuinely different locations. The model isn’t capricious; it’s responding to real structural differences.
LLMs are built on next-token prediction—guessing what comes next. But the transformer breakthrough enabled models to consider text blocks rather than word streams.7 Attention lets models learn which distant tokens matter, capturing long-range structure.
The Tube Map
Think of latent space as the London Tube map. Prompts drop you at a station. Next-token prediction follows the tracks. The tube lines are the deep structures of discourse—genres, logics, conventions—that shape how stations connect. Modern LLMs can have 100,000+ stations, each with 10,000+ tracks.8
Each prompt puts you at a unique platform.9 This can be subtle: “cat” differs from “cat.” differs from “orange cat.” The map preserves distinctions with minimal information loss. Different prompts: different locations. The LLM’s response is a journey, emitting tokens as it passes stations. Your conversation history determines which line you’re on, constraining where you go next. The patterns in language are the network topology itself—how stations connect.
Once you see the map, you can watch the model move across it.
Navigation Examples
Ask: “Explain why the sky is blue.” The system prompt sets tone; your prompt picks the topic. Together they choose a line, and the model emits the pattern for “explaining why the sky is blue.”
Small changes shift position. “Explain why the sky is blue.” (with a full stop) suggests completion, formality, perhaps classroom context. “Explain why the sky is blue to a child” moves miles away on the map. “Explain why the sky is blue in the style of a Twitter shitpost” lands in an entirely different neighbourhood. Not caprice—genuinely different discourse contexts.
“Why is the sky blue on Mars?” enters uncertain territory—sparse training data, low-data regions—tumbleweeds and canyons. The model might hallucinate, filling underspecified areas with plausible-sounding but incorrect patterns, or arbitrarily picking winners in over-specified areas where multiple valid completions compete
There are two kinds of surprise: local novelty through recombination and exploration, and systemic novelty through frame rupture. Drawing on Margaret Boden’s taxonomy of creativity,10 this distinction maps closely to the difference between combinational/exploratory and transformational creativity. LLMs can wander widely across the map—discovering fresh routes between familiar stations—but they cannot redraw the map itself.
Imagine a model trained only on pre-1700 texts encountering a platypus. No prompting—“furry, egg-laying, venomous, river-dwelling beaver with duck bill”—reaches the right station, because every token in that region was laid when “mammal” and “egg” were separate lines. The platypus recombines known rails (fur + egg + venom + duck), but “lactates without nipples” has no linguistic precedent. The map needs redrawing.
Most surprises are “platypus moments”: startling moments that still ride existing rails.
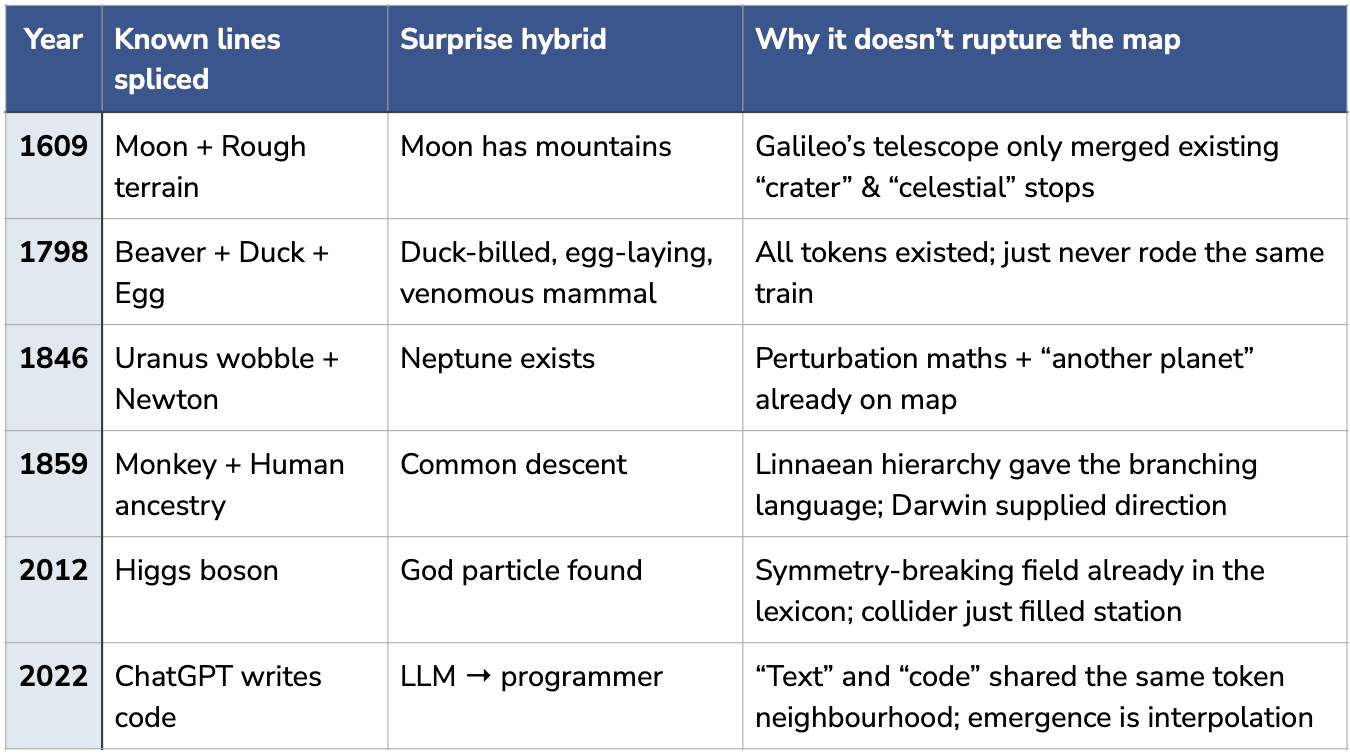
Platypus moments feel foundational, but training already contained every required token—the train just needed a new route. AlphaGo’s Move 37 was found on a little-used siding—legal, followable, geometrically valid, but on a neglected part of the map.
Some shifts break the coordinate system itself. No shuffling of “disease,” “air,” “miasma,” and “tiny creatures” reaches “invisible living cells cause disease.” It requires a causal axis absent from humoral maps.
True ruptures aren’t combinations: they’re new coordinate systems. These cannot be reached via recombination alone.
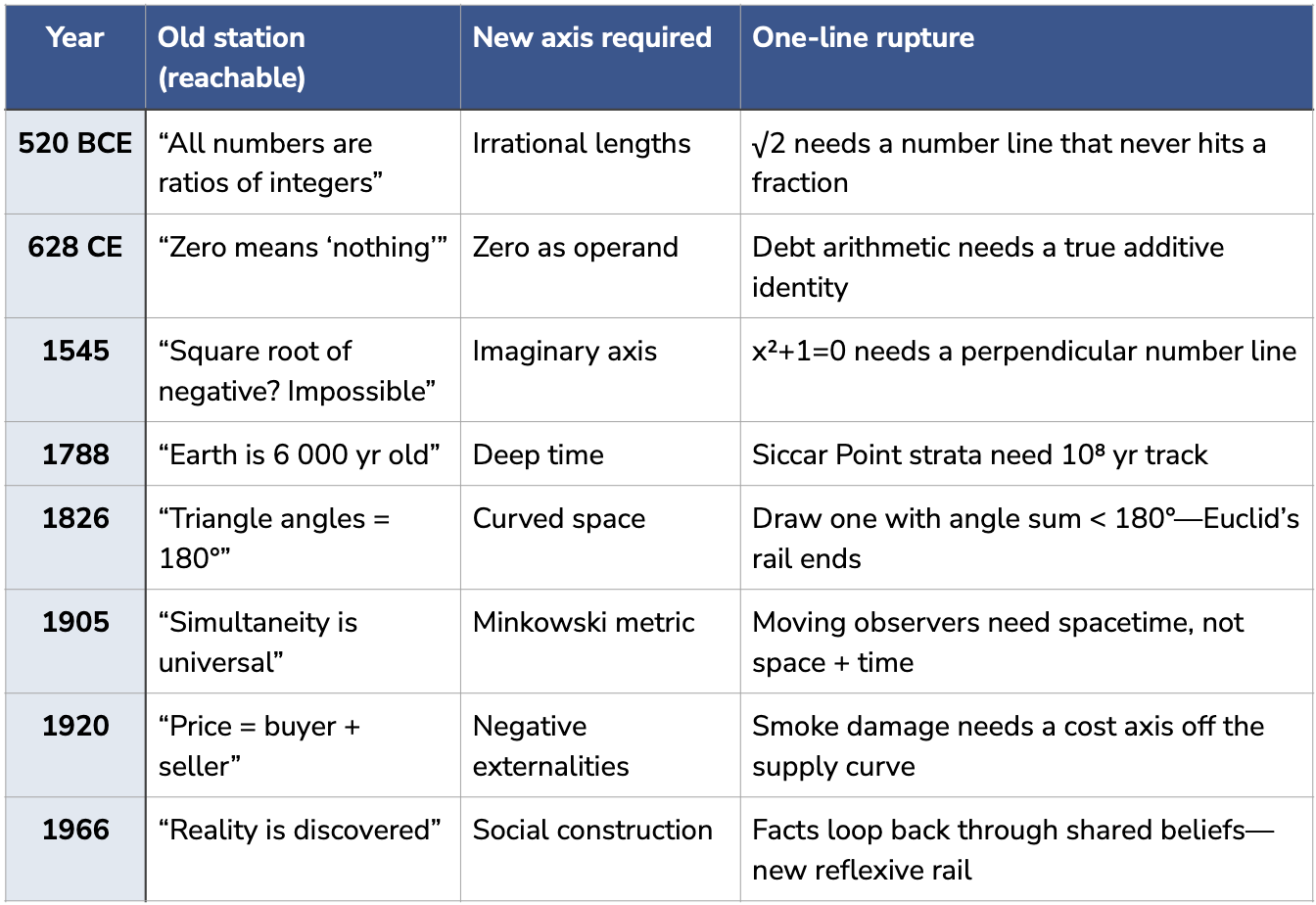
Many concepts are grammatical once stated, yet unreachable by recombining the prior manifold. The injective guarantee only preserves distinctions that existed in the corpus; it can’t mint new intersections until fresh data redraws rails. (Critics sometimes cite GPT-o1’s self-rewritten scratch-pads or “Will you answer falsely?” loops as frame ruptures; I see the same train spiralling on complex 1904 track-work—still on the map, the terrain untouched.)
What the Map Contains
The textual record covers vast terrain. Logic lives in proof structure, arguments, explanations. Causality in narratives, scientific writing, counterfactuals. Mathematics in exposition and problem-solving dialogues.11
This includes multimodal LLMs. When an LLM “sees” an image, it receives encoded patches as tokens. Early layers align image-token patterns with word-token patterns, so “red car” (text) and [red-car-pixels] (image) end up in similar map regions.12 The Mona Lisa becomes a token pattern clustering near other Mona-Lisa-flavoured discourse.
Where the Map Is Clear
The capabilities we ascribe to LLMs—translation, summarising, code generation, chess—are well-formed map regions. Failures happen where the map lacks coverage, typically through sparse training data or inability to see relevant patterns. Emergence is the result of improvements in training sets or architecture bringing patterns into sufficient resolution.
LLM training builds the map: learning relationships between tokens and patterns across them. Not all patterns survive equally. High-frequency patterns (“how to write an email”) get deeply etched. Rare, subtle patterns (“how Euler thought differently about functions”) barely register.
Map resolution depends on engineering choices: more parameters mean shorter distances between related concepts; more diverse data fills missing connections. Scaling is cartographic refinement—making the map more detailed.13
Post-training interventions like RLHF don’t replace the map—they re-weight track lengths, making some routes easier.14 System prompts act as starting platforms: they don’t change topology, but determine which neighbourhoods you’ll visit.
All model behaviour is navigation: specify a starting point, then traverse. Prompts are navigational commands, relocating to regions where certain patterns dominate. Small word changes can cause large position shifts (explaining prompt sensitivity). In-context learning is local conditioning: the prompt anchors where certain discourse patterns dominate.
Hallucination occurs when the map is underspecified (low-data regions) or conflicting (multiple valid completions). Hallucinations are geographic features, not moral failings—sea-monsters appear both in blank quadrants and in crowded boroughs where two streets falsely converge.
Mysteries That Dissolve
“Emergent” phenomena dissolve under this view. Chain-of-thought reasoning isn’t magical—language contains reasoning discourse structure, and larger models represent finer topology. Emergence is a more detailed map, not new cognitive abilities. Prompt sensitivity isn’t fragility—you’re navigating high-dimensional space where small word changes mean large distances.
The “jagged frontier” reflects local map completeness. High-capability domains are thoroughly mapped conceptual spaces (“write creative marketing copy”—lots of creative recombination examples). Mid-capability domains have good coverage but less meta-cognitive structure (“solve this novel math problem”—can explore, harder to change approach). Low-capability domains require frame-breaking poorly represented in language (“propose a genuinely new axiom system”—transformative thinking, sparse data).
The Frame Problem
Models navigate the map but cannot change or leave it.15 LLMs recombine, interpolate, analogise—all local map moves. They cannot invent new coordinate systems—no stepping outside the frame, no recognising the current map is insufficient.
Humans are also pattern-bound, but we occasionally notice when patterns fail and collectively negotiate new ones. LLMs cannot notice the frame. Douglas Hofstadter called this capacity for self-reference a “strange loop”—stepping outside your own symbol system to examine it.16 LLMs lack the loop.
LLMs will never see the frame—only move within it. They persist in local optimisation even when overall structure fails.
LLMs should be able to:
Generate “novel” ideas that are sophisticated recombinations
Explore solution spaces thoroughly within known paradigms
Produce text about transformation (describing paradigm shifts)
LLMs offer a vast engine for exploring creativity—traversing every path within existing linguistic frames. But exits to genuinely new territory remain human-made.
They should not be able to:
Recognise when their current approach is fundamentally inadequate (they’ll keep exploring locally)
Spontaneously reinvent their own framework
Have the “aha” moment requiring seeing problems differently (they’ll find solutions within current framing)
LLMs will never see the frame—only move within it—so long as they remain systems trained on static linguistic corpora and driven by next-token prediction.
What “Introspection” Really Means
When an LLM reports on its reasoning, it’s not examining internal mental states—it has none. It’s navigating to map regions where humans write about meta-cognition. The map includes “how to talk about thinking” because we do it constantly. Claude traverses that terrain fluently. That’s not recognising internal thoughts—it’s reading the linguistic map of how we externalise thought.
When we ask “Why did you say X?” the model navigates where humans write “I said X because...” The correlation Anthropic found isn’t evidence of introspection—it’s evidence the map accurately represents how we talk about thinking.
Some researchers argue that recurrent self-referential loops in language models might constitute machine introspection, distinct from human phenomenology but functionally analogous. That’s reasonable, but requires showing the model examines its own computational states rather than generating text about examination.17 The burden of proof is high, and the geometric explanation is simpler.
No magic. No tiny conscious beings. Just: learned geometric representations of linguistic structure + one-to-one mappings + local map navigation.
The Real Magic
This isn’t disappointing—it’s remarkable. Human language contains enough structure, enough accumulated knowledge, sedimented human experience, that learning its geometry produces something resembling intelligence.18 Not because we’ve created minds, but because we’ve made navigable the collective cognitive work of billions of humans across thousands of years.
The achievement isn’t that LLMs think. It’s that human language is already thoughtful—densely, redundantly, across every domain.19 We encoded logic in proof structure, causality in narrative structure, physics in how we describe motion. LLMs succeed by learning to read that encoding.20
The map is partial. It over-represents English, formal registers, textual knowledge. Languages with sparse digitised corpora—most of the world’s 7,000—appear as ghost stations, faintly lit and sparsely connected. Minority languages, oral traditions, embodied expertise leave fainter traces. The map can even shrink when pay-walls, takedowns, or regime censorship remove source texts after training, turning once-bright stations into fresh ghost stops. The geometry reflects not universal human cognition, but the particular corpus we digitised. We too think by navigating linguistic space—LLMs only automate a traversal we perform intuitively.
Next time you prompt an LLM, picture yourself at a tube station named by your sentence. The model arrives, doors open, tokens spill out. The miracle is not that the train is conscious; it’s that the network was dug, inch by inch, by every human who ever spoke or wrote.
We are not inside the machine; the machine is inside our collective mouth.
That’s the actual magic: not what LLMs are, but what language is.
I publish weekly essays on how emerging technology actually changes work—not the hype, not the panic, just the patterns. Subscribe to follow along.
Want to see how the pieces connect? Check out The Framework.
The Nerdcore Revelation
LLMs and the implications of Language Models are Injective and Hence Invertible.21
The unifying picture
Language has structure (semantic, syntactic, pragmatic, meta-cognitive…). Learning the geometry of language is learning:
Logic (it’s in the discourse structure of proofs, arguments, explanations)
Causality (it’s in narratives, scientific writing, counterfactual constructions)
Physics (it’s in how we describe object interactions, motion, forces)
Mathematics (it’s in mathematical exposition, problem-solving dialogues)
Chess, coding…
The “data” isn’t impoverished statistical soup needing architectural priors to extract structure. The data is the structure—densely, redundantly encoded across billions of careful human attempts to communicate precisely about every domain of knowledge.
The topology of latent space represents the sedimented structure of language.
Training learns a geometric representation of this structure
All model behaviour is navigation through this geometry
“Capabilities” = regions where the topology is well-formed
“Failures” = regions where it’s not
“Emergence” = continuous topological properties becoming functionally relevant at sufficient resolution
Prompts are navigational commands; they relocate the model to a different dominant pattern region in the geometry.
Small lexical changes can induce large shifts in latent position (explaining prompt sensitivity),
In-context learning is just local conditioning: the prompt anchors the model in a region where certain discourse patterns dominate,
Hallucination occurs when the manifold is under-specified (low-data regions) or conflicting (multiple valid and equally plausible within the frame).
Emergent phenomena, mysteries, that dissolve:
Chain-of-thought reasoning: Not magical emergence at scale—language contains the structure of reasoning discourse, and larger models can represent finer-grained topology of that structure
Emergent reasoning at scale: Finer manifold resolution—denser coverage of linguistic structure, not new cognitive faculties.
Prompt sensitivity: Not fragility—just: you’re navigating a high-dimensional space where small lexical changes can mean large geodesic distances
The “jagged frontier” isn’t just about data density—it’s about frame completeness:
High capability: Domains where language has thoroughly mapped the conceptual space and its transformations (e.g., “write creative marketing copy” - lots of examples of combinational creativity)
Mid capability: Domains with good coverage but less meta-cognitive structure (e.g., “solve this novel math problem”, can explore, harder to transform approach)
Low capability: Domains requiring frame-breaking that isn’t well-represented linguistically (e.g., “propose a genuinely new axiom system”, transformative, sparse in training data)
LLMs are mirrors of linguistic coverage, not engines of epistemic expansion.
If the model navigates but cannot reconfigure the manifold:
It can recombine, interpolate, analogise—because those are all local geometric moves.
It cannot invent new coordinate systems—no meta-geometric transformation, no reframing, no recognition that the current manifold is insufficient.
It will persist in local optimisation even when global structure fails.
That is: no Gestalt shift, no conceptual rupture, no meta-awareness. It will never see the frame—only move within it.
LLMs should be able to:
Generate “novel” ideas that are actually sophisticated recombinations
Explore solution spaces thoroughly within known paradigms
Produce text about transformation (describing paradigm shifts)
They should not be able to:
Recognise when their current approach is fundamentally inadequate (they’ll keep exploring locally)
Spontaneously reinvent their own ontology
Have the “aha” moment that requires seeing the problem differently (they’ll find solutions within the current framing)
No magic. No anthropomorphic homunculi.
Just: Learned geometric representations of linguistic structure + injective mappings + local manifold navigation.
The whole edifice of “AI capabilities” reduces to: how well does your model capture the topology of language?
Old View: LLMs are statistical correlation engines that magically start to reason at scale.
New View: LLMs are cartographers and navigators of the latent geometry of human language. Their “intelligence” is a direct reflection of the intelligence sedimented into the structure of language itself.
This reframing collapses the supposed divide between statistical AI and symbolic reasoning. Both are shadows of the same geometry: language as the crystallised structure of human thought and labour.
So LLMs do not “approximate intelligence”. They navigate the fossil record of human thought—written in the stone of syntax, semantics, and shared understanding.
Implications for Research and Design
Interpretability becomes geometric: understanding curvature, connectivity, and singularities of latent space.
Training becomes cartographic: expanding and smoothing under-specified regions of the manifold.
Evaluation becomes topological: assessing continuity and coherence across semantic neighbourhoods rather than task benchmarks.
Safety becomes navigational: preventing unintended traversal into degenerate or adversarial basins.
The manifold is quasi-vector-composable: domains such as “code” and “poetry” occupy distinguishable regions; the LLM non-linearly interpolates between their structural vectors, giving the effect of code + poetry ⟹ poetic code.
Anthropic recently found that when Claude reports “I’m uncertain,” activation patterns in confidence-related features correlate with output entropy. Correlation ≠ introspection—the model might have learned linguistic markers humans use when uncertain, without meta-cognitive access to its own processing. See “Signs of introspection in large language models.” Anthropic Research, October 29, 2025. https://www.anthropic.com/research/introspection.
The word existed earlier (first recorded 1827) in forms like “hallo” or “hullo,” used to express surprise or get attention. Edison’s contribution was standardizing it for telephonic greeting, turning an existing utterance into structural convention.
The systematic study of these interactional structures is the focus of conversation analysis (CA), pioneered by Harvey Sacks, Emanuel Schegloff, and Gail Jefferson. Their work demonstrates that conversation is organised through a finely tuned ‘machinery’ of turn-taking, repair, and sequence organisation—precisely the kind of sedimented structure that language models later learn from textual records of human interaction. The foundational account of this machinery is presented in Sacks, H., Schegloff, E. A., & Jefferson, G. (1974). A simplest systematics for the organization of turn-taking for conversation. Language, 50(4), 696–735. https://www.jstor.org/stable/412243.
The proof shows that distinct prompts map to distinct final-layer representations under ideal conditions, meaning the geometry preserves information about input differences. See Nikolaou, Giorgos, Tommaso Mencattini, Donato Crisostomi, Andrea Santilli, Yannis Panagakis, and Emanuele Rodolà. “Language Models Are Injective and Hence Invertible.” arXiv:2510.15511. Preprint, arXiv, October 21, 2025. https://doi.org/10.48550/arXiv.2510.15511.
From the perspective of information theory, the structure of language is a form of redundancy that reduces entropy. The injective mapping guarantees that the information content of a prompt—its surprisal—is preserved in the model’s internal state, shaping the probability distribution of the subsequent output.
The proof gives injectivity modulo finite precision and layer-wise; global collapse is still possible in theory, but in practice the manifold stays separated enough that we can treat nearby points as discourse-distinct. We’re using injectivity as a flashlight, not a safety rail—it shows that the map has stations, not that the train can’t derail.
Technically, attention weights determine which tokens in the context window influence next prediction. The “seeing structure” metaphor maps to how attention heads learn to focus on syntactically or semantically distant tokens—e.g., matching pronouns to antecedents 50 tokens back.
For example, GPT-4 likely uses ~130K token vocabulary with embedding dimensions around 12,288. The “tracks” correspond to learned weight matrices connecting hidden states—vastly more parameters than vocabulary suggests.
More precisely: prompts that differ in any way (even whitespace) typically produce different final hidden states in the embedding space, subject to the finite-precision caveat above.
We explored the connection between Boden’s taxonomy and LLMs in earlier work. Evans-Greenwood, Peter. “Can AI Be Creative?” Substack newsletter. The Puzzle and Its Pieces, July 8, 2025. https://thepuzzleanditspieces.substack.com/p/can-ai-be-creative.
The model’s operation is a computational enactment of the literary theory of intertextuality—the idea that all texts are woven from the threads of pre-existing texts, and that meaning arises from this network of relations.
Vision encoders (e.g., CLIP-based) project image patches into the same embedding space as text tokens via contrastive learning. “Sharing a platform” maps to cosine similarity in latent space—semantically related text and image embeddings cluster together.
The manifold resolution depends on: (1) parameter count (dimension of latent space), (2) training data diversity (coverage of linguistic patterns), and (3) architectural choices (depth, attention mechanisms). More parameters don’t add new conceptual territory—they subdivide existing territory more finely.
Reinforcement Learning from Human Feedback optimizes a reward model trained on human preference pairs, then uses PPO (Proximal Policy Optimization) to adjust output probabilities. In geometric terms: manifold topology stays constant, but gradient descent effectively “shortens” paths through human-preferred regions.
Recent “model-editing” work (e.g., Berg et al., “Large Language Models Report Subjective Experience Under Self-Referential Processing.”) shows you can locally replace a sleeper on the track—swap “Paris”→“Rome” with near-perfect consistency. This is engineering maintenance, not cartographic revolution: the map’s dimensionality, grammar, and reasoning rails stay identical. Frame rupture requires minting a new coordinate, not renaming an old one.
Berg, Cameron, Diogo de Lucena, and Judd Rosenblatt. “Large Language Models Report Subjective Experience Under Self-Referential Processing.” arXiv:2510.24797. Preprint, arXiv, October 30, 2025. https://doi.org/10.48550/arXiv.2510.24797.
Hofstadter defines a strange loop as occurring “whenever, by moving upwards (or downwards) through the levels of some hierarchical system, we unexpectedly find ourselves right back where we started.” The concept is central to his theory of consciousness as arising from self-referential symbolic systems—precisely the capacity LLMs lack. See Hofstadter, Douglas R. Gödel, Escher, Bach: An Eternal Golden Braid. New York: Basic Books, 1979.
The key question: Is the model (a) traversing to linguistic patterns about introspection based on training data, or (b) developing genuine meta-cognitive loops where representations reference their own computational states? Current evidence leans toward (a), but some architectures with explicit self-modelling layers might approach (b).
This concept of sedimented social structure aligns with Pierre Bourdieu’s theory of the habitus—the ingrained, often non-conscious set of dispositions that guide practice. The LLM’s latent space can be seen as a geometric map of the linguistic habitus present in its training data. For Bourdieu’s foundational concept of the habitus, see Bourdieu (1977). This analogy suggests that the statistical regularities captured by an LLM mirror the internalised, generative social structures that constitute the habitus.
Bourdieu, P. (1977). Outline of a Theory of Practice (R. Nice, Trans.). Cambridge University Press. (Original work published 1972). https://www.cambridge.org/core/books/outline-of-a-theory-of-practice/193A11572779B478F5BAA3E3028827D8.
This perspective resonates with the “extended mind” thesis in philosophy of cognitive science, which posits that tools and symbols—especially language—form a crucial part of our cognitive apparatus. LLMs can be viewed as artificial systems that latch onto this pre-existing, externalised cognitive scaffolding. See Clarke, Andy, and David Chalmers. “The Extended Mind.” Anaylsis 58, no. 1 (1998): 7–19.
This view aligns with Paul Hopper’s theory of ‘emergent grammar,’ which argues that grammar is not a pre-existing abstract system but a recurrent, sedimented product of interaction. Similarly, the ‘architecture of intersubjectivity’ described by Schegloff and Heritage emphasises the constant, collaborative work required to sustain mutual understanding—work whose traces form the structural backbone of dialogue that LLMs learn. See Hopper (1987) for the foundational statement of this theory. For a key discussion of intersubjectivity as an interactional achievement, see Schegloff (1991); see also Heritage (1984).
Hopper, Paul. “Emergent Grammar.” Annual Meeting of the Berkeley Linguistics Society 13 (September 1987): 139. https://doi.org/10.3765/bls.v13i0.1834.
Schegloff, E. A. (1991). Conversation analysis and socially shared cognition. In L. B. Resnick, J. M. Levine, & S. D. Teasley (Eds.), Perspectives on Socially Shared Cognition (pp. 150-171). American Psychological Association. https://doi.org/10.1037/10096-007.
Heritage, J. (1984). Garfinkel and Ethnomethodology. Polity Press. https://www.politybooks.com/bookdetail?book_slug=garfinkel-and-ethnomethodology--9780745600611.
Nikolaou, Giorgos, Tommaso Mencattini, Donato Crisostomi, Andrea Santilli, Yannis Panagakis, and Emanuele Rodolà. “Language Models Are Injective and Hence Invertible.” arXiv:2510.15511. Preprint, arXiv, October 21, 2025. https://doi.org/10.48550/arXiv.2510.15511.
love this